Hey guys. I’m running into a weird situation here that debugging is becoming extremely hard to debug.
I have made a post here Cloudflare caching in a quasar app thinking that the problem was about caching.
We are having hydration errors in our webapp codotto.com ONLY after a few hours (or minutes depending on website traffic). As soon as I redeploy the app, everything works well. No hydration errors anymore.
We had the idea that it was caching but we have disabled caching completely in our cloudflare dashboard:
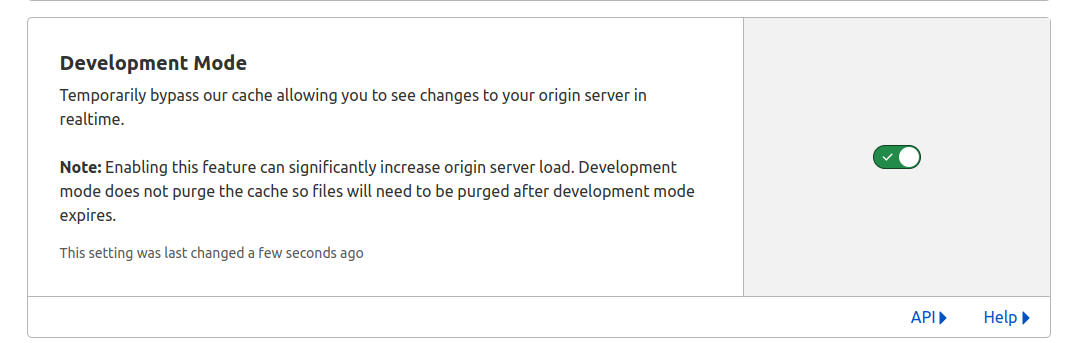
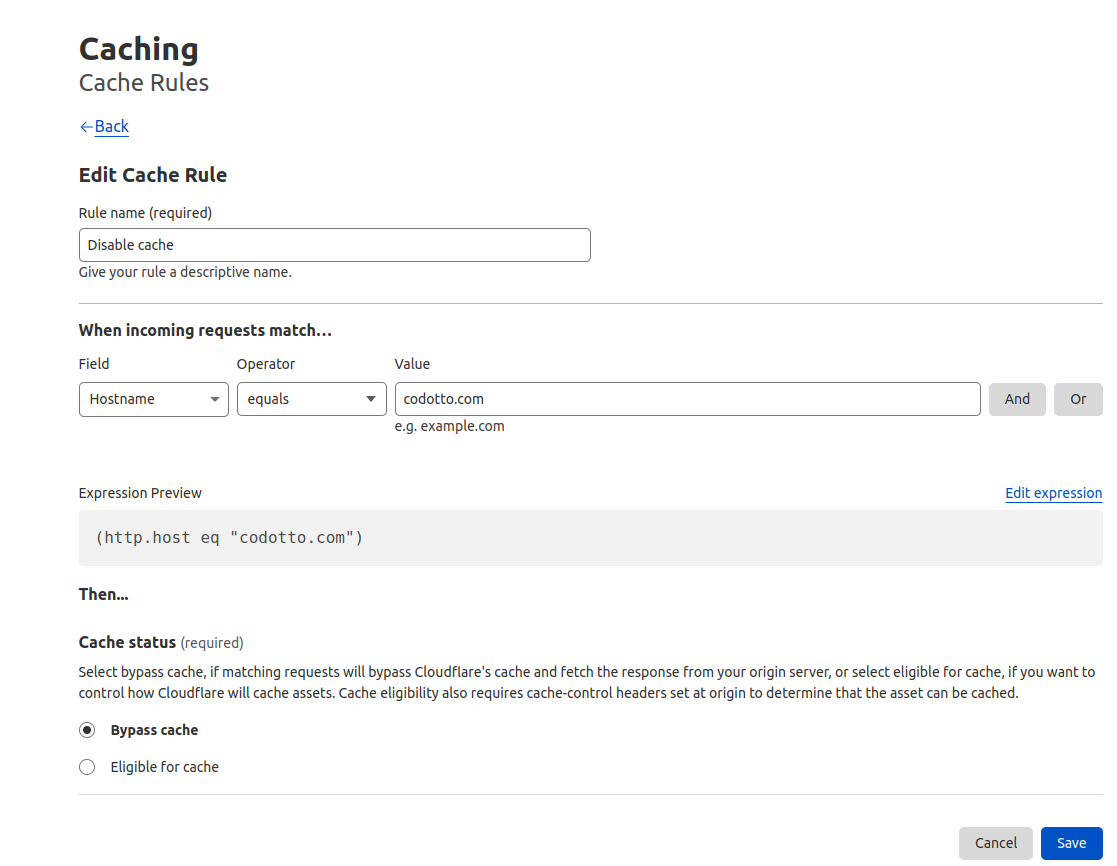
Then we can verify that the cache is not being used:
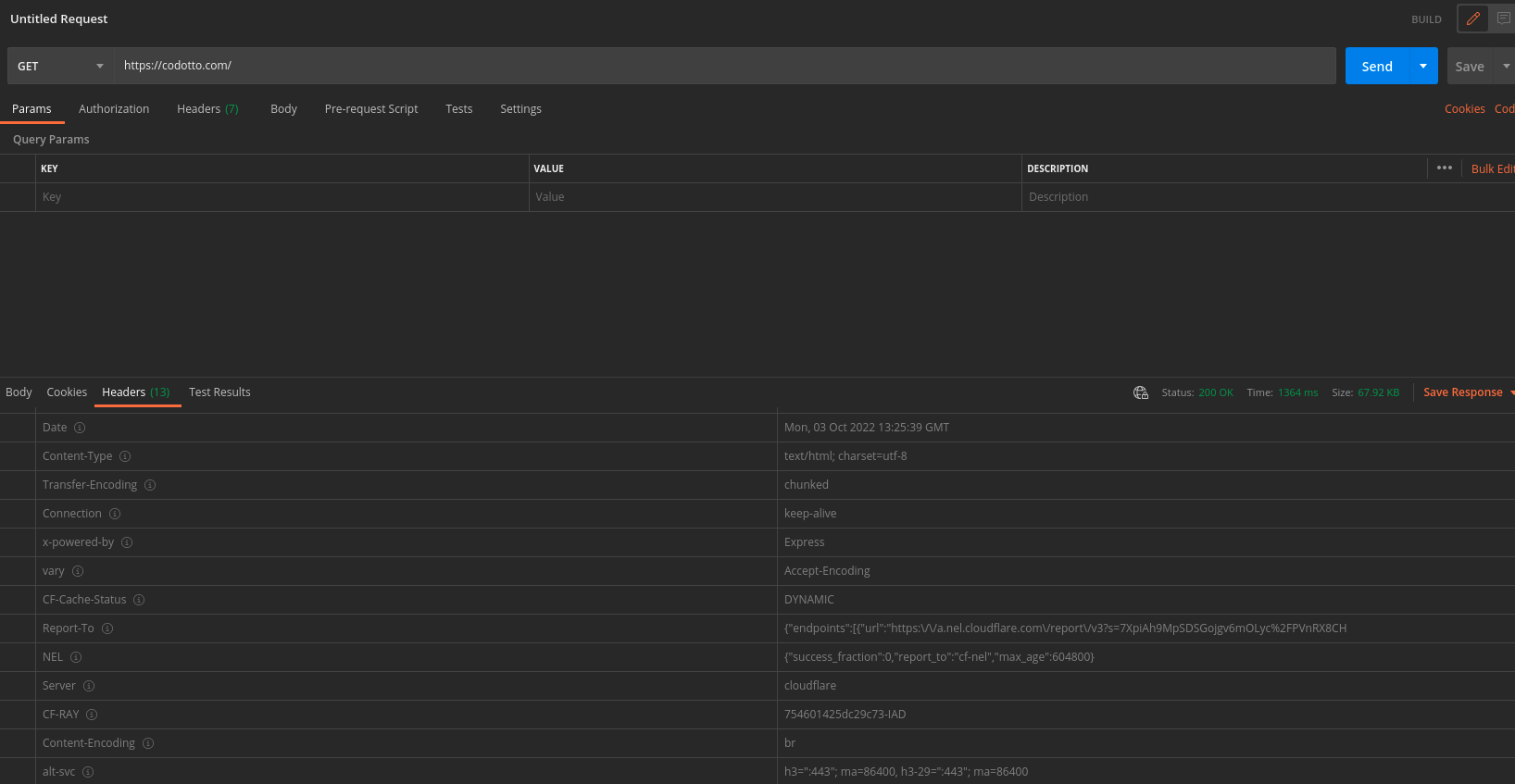
Note the CF-Cache-Status set to DYNAMIC (refer to here to see that when you have DYNAMIC set in CF-Cache-Status header it means that cache is not being used).
Locally the app works great and we are not able to reproduce the issue locally and in staging as well. This only happens in production. Here we have configurations for pm2 settings:
production
// DO NOT MODIFY THIS FILE. THIS FILE IS RECREATED WITH EVERY DEPLOYMENT.
module.exports = {
name: "codotto.com",
script: "index.js",
args: "",
log_type: "json",
cwd: "/home/cleavr/codotto.com/artifact",
// Note: We detected that this web app is running on a server with multiple CPUs and hence we are
// setting *instances* to "max" and *exec_mode* to "cluster_mode" for better performance.
instances : 1, // change the value to "1" if your server has only 1 CPU
// exec_mode : "cluster_mode", // remove this line if your server has only 1 CPU
env: {
"PORT": 7145,
"CI": 1,
"NUXT_TELEMETRY_DISABLED": 1
}
}
staging
// DO NOT MODIFY THIS FILE. THIS FILE IS RECREATED WITH EVERY DEPLOYMENT.
module.exports = {
name: "staging.codotto.com",
script: "index.js",
args: "",
log_type: "json",
cwd: "/home/cleavr/staging.codotto.com/artifact",
// Note: We detected that this web app is running on a server with multiple CPUs and hence we are
// setting *instances* to "max" and *exec_mode* to "cluster_mode" for better performance.
instances : 1, // change the value to "1" if your server has only 1 CPU
// exec_mode : "cluster_mode", // remove this line if your server has only 1 CPU
env: {
"PORT": 9892,
"CI": 1,
"NUXT_TELEMETRY_DISABLED": 1
}
}
We are running out of ideas and this only happens in production, making it extremely hard to debug and we are scoping the problem down to the server configuration.
We have tried following this guide on Quasar’s website to debug hydration errors but haven’t gotten us anywhere.
In case you would like to reproduce the bug, you will need to sign up to an account in codotto.com, then visit https://codotto.com so that you are redirected to the dashboard instead of the landing page.
Can anyone here help or explain why we have these hydration errors?