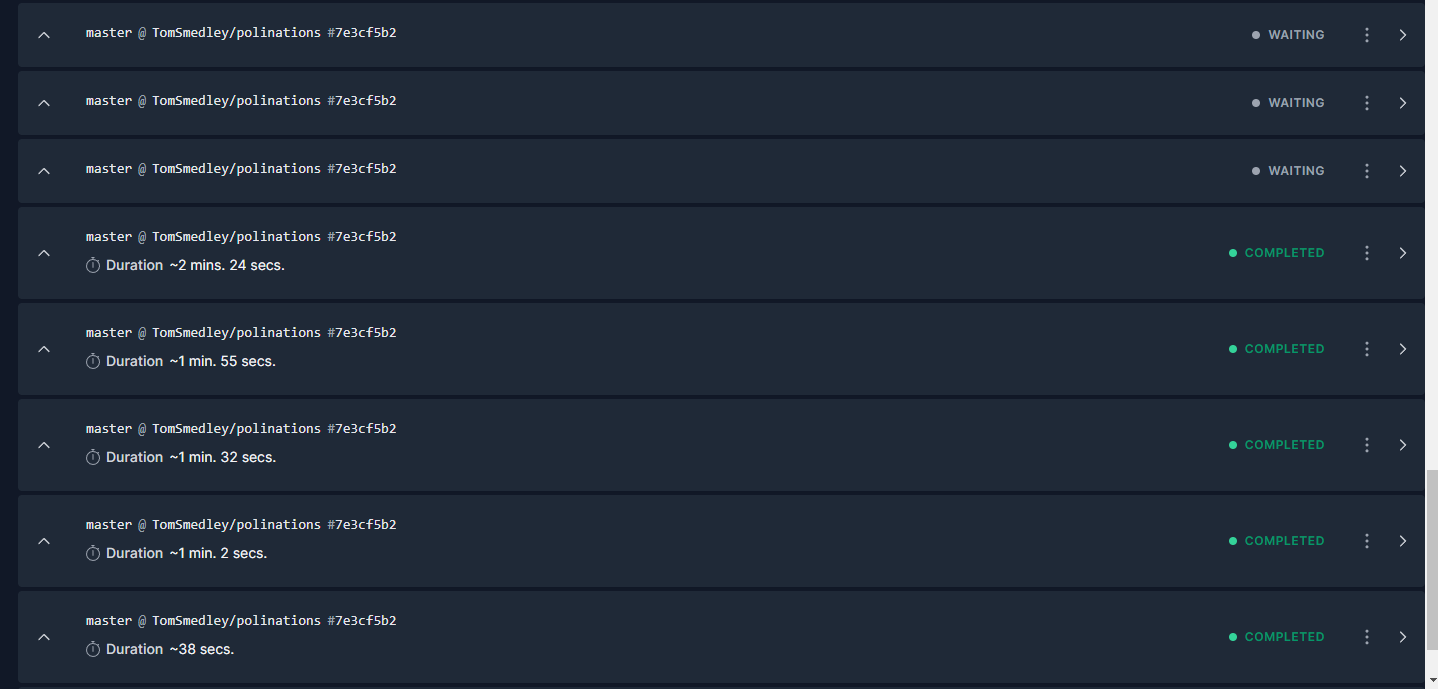
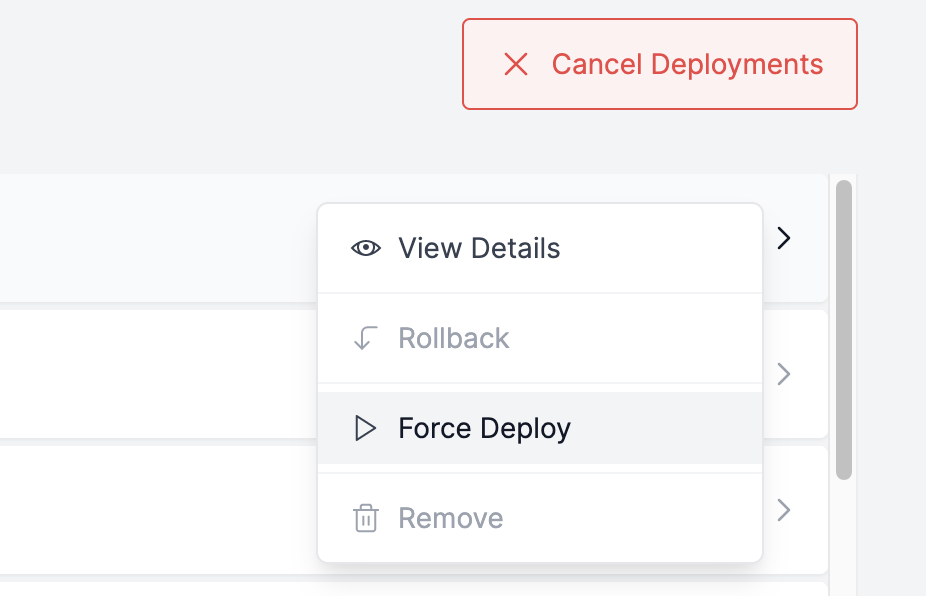
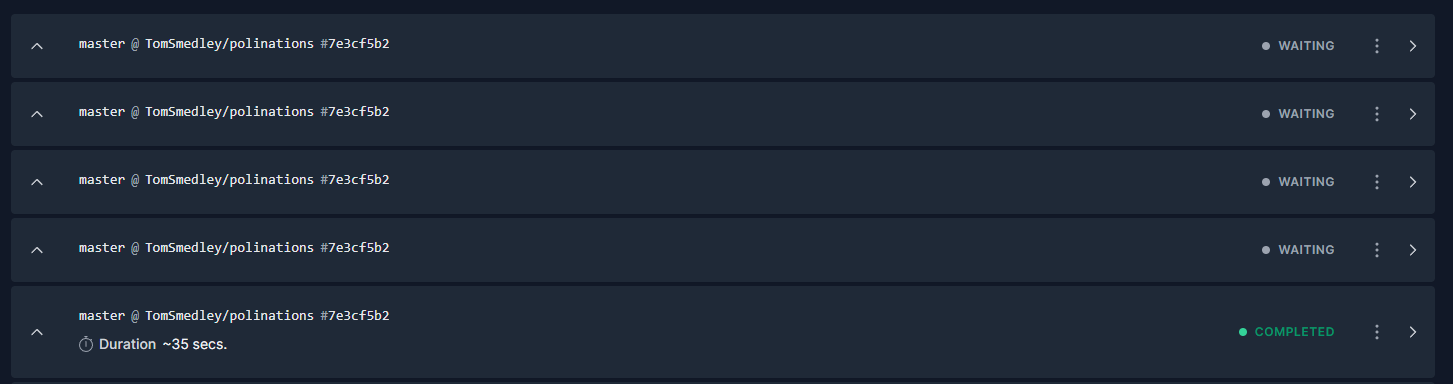
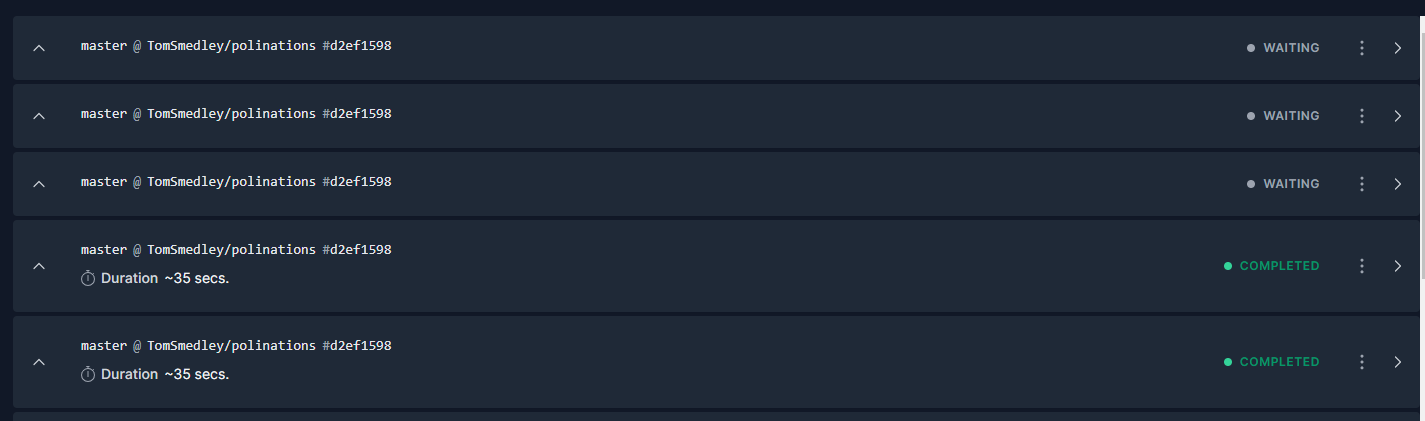
I had a client contact saying their website isn’t updating anymore. I’ve taken a look and it seems that the build times took a massive dive before freezing completely.
This is Astro being built and I know there has been issues with Astro before in the past. I was wondering if there is any ideas what may be causing this?
My concerns is if this happens again and I’m on holiday for example. They have only had the CMS for a short time and this problem has cropped up instantly. Just looking for some reassurance really.
What shall I do in the meantime? I can create a new environment and leave this alone so you can test it? Or will the queue also affect other sites from deploying?
To confirm you don’t need to use my environment to test what has caused it to freeze? I just wouldn’t want to clear all the deployments and it not give you chance to test it.
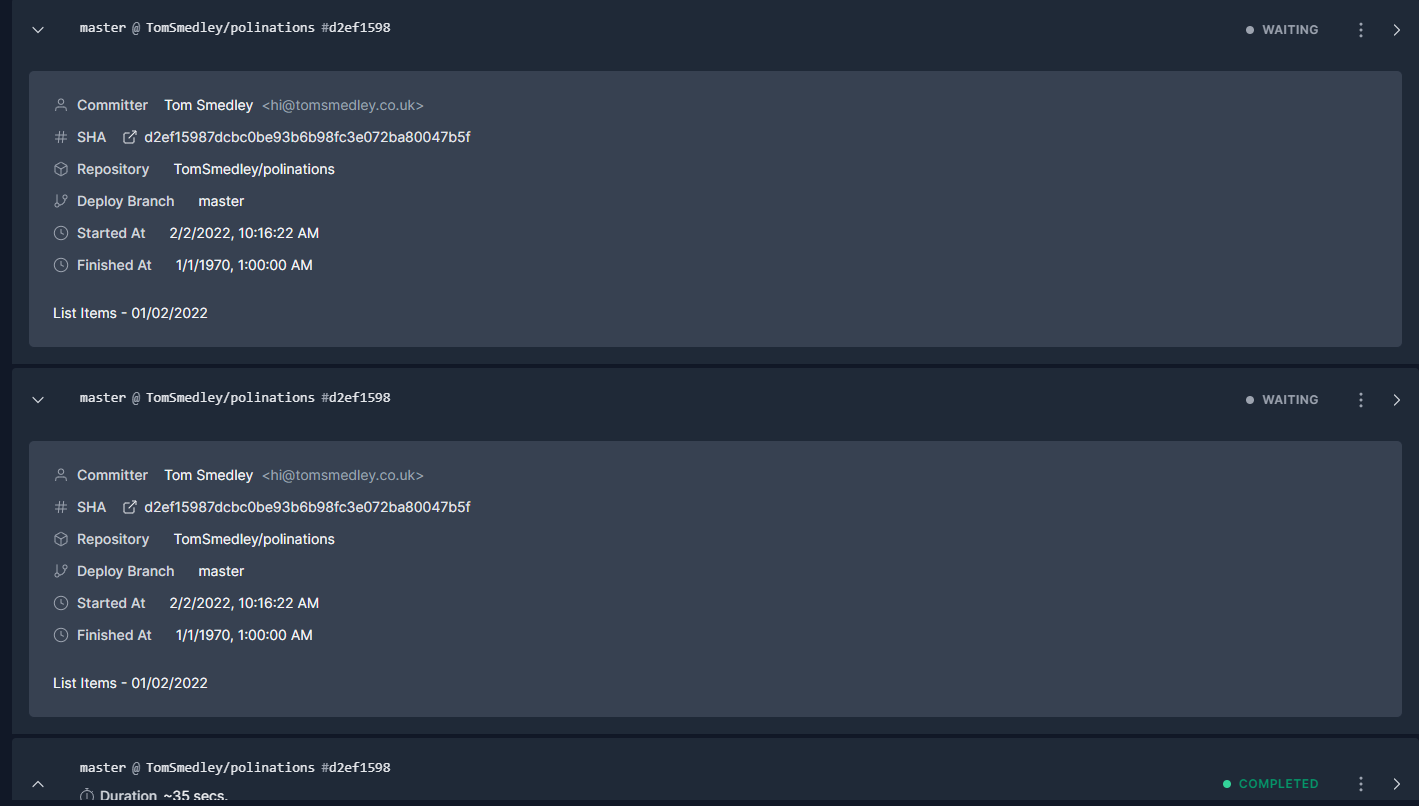
I have added a new site and created a new deployment. I’ve left the old one as it is for you to test. If you can see my account it’s “PoliNations Static (Froozen)”.
I look forward to hearing what the issue may have been. Keep up the great work, Cleavr is an amazing piece of software!
I could see the first deployment is completed. Do you remember after enabling which hook the deployment started getting stuck or is there any thing else after which deployment started to get stuck?
So I think I understand the problem. So the “deployment trigger hook” which the CMS is firing, I had the CMS do this on any update. The issue is when there was repeaters, if was firing an update for each repeater item. This means, in this instance the “deployment trigger hook” was fired 3 times at the same time. This has caused a complete freeze.
This also means if there are multiple people editing the CMS at the same time, this issue could occur. I wonder if there is a “Waiting” or “In Progress” deployment, a new deployment would cancel that and start a new one. That way the queue doesn’t get rushed causing a backlog to effectively do the same thing.
I’m unsure what causes it to get stuck in “Waiting” however, you would expect it to make its way through the queue of deployments. There must be some sort a “rush” happening causing the system to panic and shut down it’s process?
Hope any of this is helpful,
Tom
EDIT:
This is still an issue with even two firing at the same time. Seems to be still happening now even after I’ve limited the amount of calls to the deployment trigger hook.
We’re investigating the issue right now. We’ll try to find out why deployments are stuck in waiting and get it fixed as a first step so that you’ll be unblocked for now.
We have found one path which could lead to this but in a rare case - the health checks we perform after each deployments could be waiting to complete and blocking the next deployment. We have already fixed the bug as currently in QA.
We are also thinking of a way to not fire deployments consecutively like what happened to you. If you have any suggestions on how to better handle it, we would love to hear them.
Sorry about the issue and thank you for your support and patience.
I’ve upgraded the server to 2 vCPU hoping this will help the issue, but doesn’t seem to have an effect. It’s if you have two “deployment trigger hook” fired at the same time.
At the moment, any time they make CMS changes I have to manually deploy, I can’t babysit the server like this.
EDIT:
“We are also thinking of a way to not fire deployments consecutively like what happened to you. If you have any suggestions on how to better handle it, we would love to hear them.”
I think it would be fine to cancel any duplicated requests at the same time and only action the most recent. I can’t think of any example in which this would cause issues but it would prevent a rush from the CMS.
The CMS is Directus, basically it has webhooks but if you have repeaters for relationship data for example you have a list of “events” you also have a “featured events” relationship on the homepage. Adding new events or re-ordering the events on the homepage will trigger both an update for “homepage” and also “events”. This might be something I can fix on Directus side, but I’m unsure. It also means that there is a possibility of freezing deployments if they update content quickly which worries me.
Just want to say that Cleavr is an amazing bit of software and I completely believe in it. The support is amazing and you guys are doing an amazing job. I really appreciate you looking in to this.
Hello, I’m having the same issue,
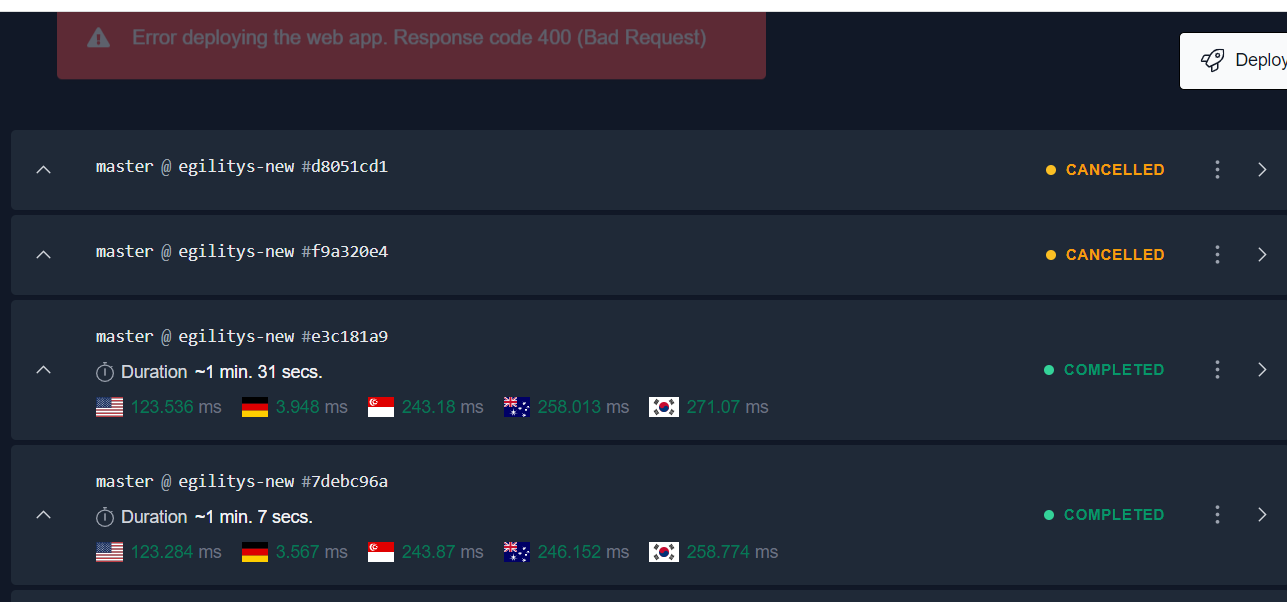
When I push into my branch automatically I can see a new deployment waiting.
However, it stuck on waiting forever. so I tried to force it and got a 400 response code
I also tried to cancel and re-deploy but got the same 400 response code