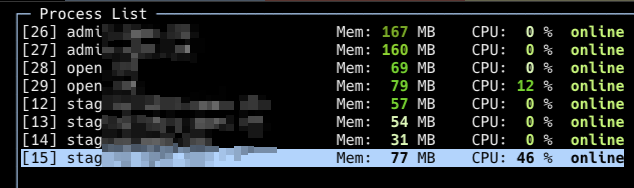
We’ve been increasingly receiving issues concerning cluster mode not running properly on servers with multiple CPU / Cores. An indication of this is high CPU usage and constant restarts if you check the NodeJS heartbeat in the services section.
This mainly impacts Strapi and Nuxt apps running on Node v16 and any other app types that start via the npm start command as opposed to having a specific file pointed to - ie, server.js, main.js, etc.
If you are using Node v16 and a server with 1 CPU, then you shouldn’t experience this issue.
Work-a-rounds
As we’re looking more into the issue and how we might resolve it, there are a couple of work-a-rounds you can try.
-
From the services section, uninstall Node 16 and install Node 14; then you’ll need to click the ‘repair’ button on the ellipsis menu after Node 14 installs. This resets the apps and PM2 so they run correctly.
-
If you need to keep node 16, then you can update your web app to point directly to the start file. However, this solution won’t work for using the GHA integration at the moment. In web app > settings > build:
2.1 If you have anything listed in the ‘Artifact Path’ box, remove it and deploy out the app before moving to next step (this will make the site not render so please only do this during maintenance downtime)
2.2 Replace Entry File fromnpmwith./node_modules/nuxt/bin/nuxt.js(note, if using Strapi, then replacenuxtwithstrapi)
 along the way!
along the way!